Core Idea
Affordance = Geometry x Interaction.
Geometry identifies action-supporting parts. Interaction tells which part an action engages. We probe both in VFMs and compose them without affordance training.
Problem
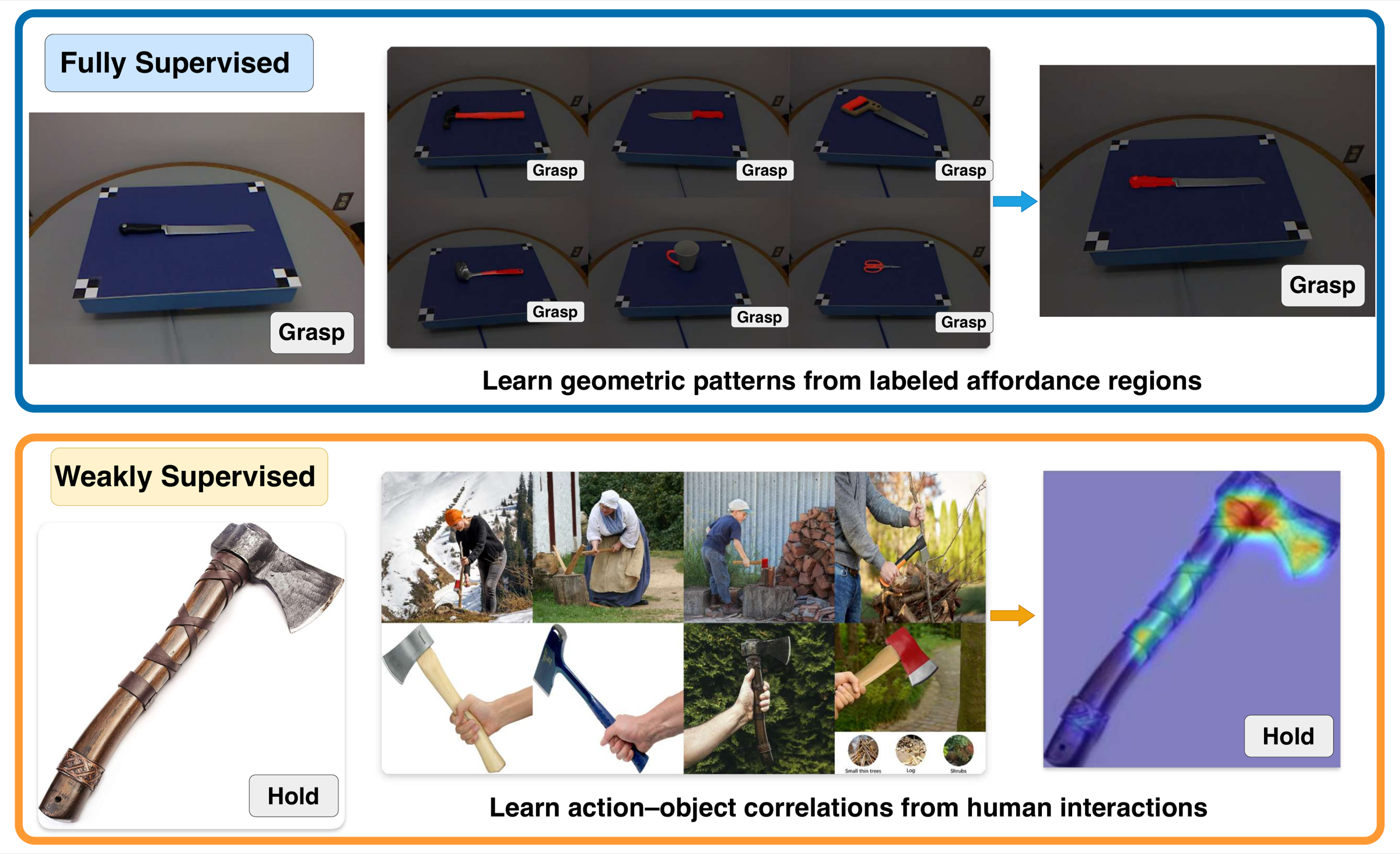
What makes an affordance region meaningful?
Fully supervised methods learn labeled regions. Weakly supervised methods learn action-object correlations. Both can predict heatmaps, but neither alone explains why a region is actionable.
Decomposition
The paper splits affordance into two observable primitives.
Geometry: where action can be supported.
Object parts, shape, and spatial structure define plausible support regions.
Interaction: how action engages an object.
Verb-conditioned priors identify which part matters for a specific action.
Composition: whether the two primitives can produce affordance.
Training-free fusion tests whether geometry and interaction are actually composable.
Geometry Evidence
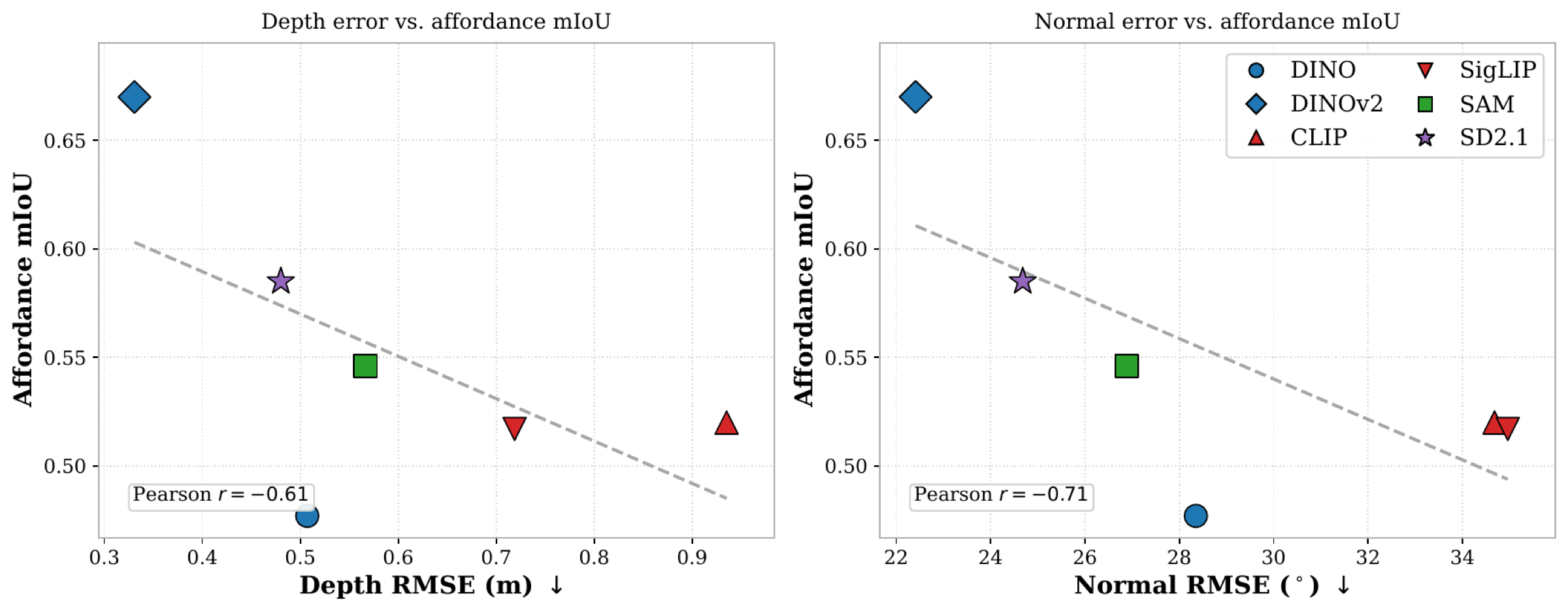
Geometry-aware VFMs expose action-relevant object parts.
DINO-style features reveal coherent part-level structure, while geometric awareness correlates with affordance performance. Geometry gives spatial support, but not the action by itself.

Interaction Evidence
Generative VFMs encode verb-conditioned interaction priors.
Flux Kontext attention localizes plausible contact regions. The verb changes spatial attention, not just object semantics.


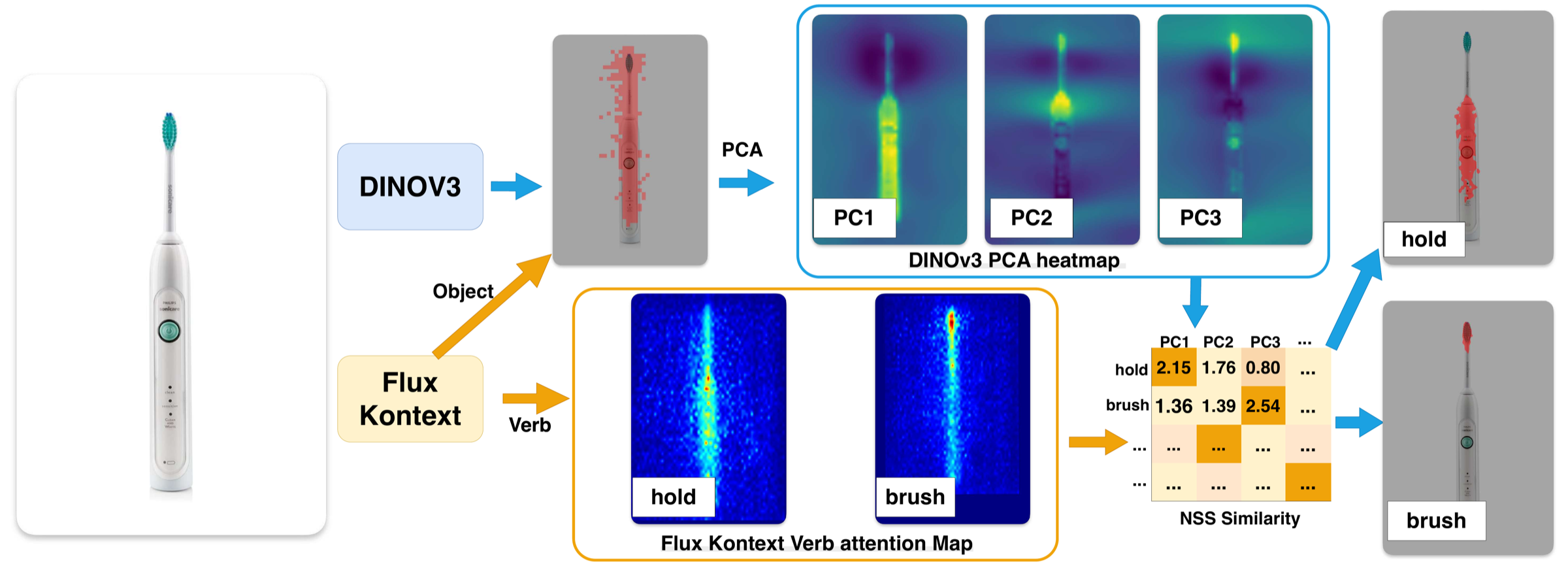
Mechanism
DINOv3 geometry and Flux interaction can be composed training-free.
- DINOv3 extracts part-level geometric components.
- Flux Kontext provides object attention and verb attention.
- NSS measures which geometric component aligns with the verb prior.
- The selected component becomes a verb-specific affordance mask.
Results
Geometry sharpens interaction into affordance.
Interaction-only maps already carry affordance signal. Adding geometry makes the prediction sharper and more part-specific, improving KLD, SIM, and NSS without affordance training.

lower is better
higher is better
higher is better
Boundary
Where the current mechanism fails.
This is not proof of embodied causal understanding. It shows composable visual primitives, with failure modes when generative edits or object attention become unreliable.

Generative object duplication
The editing model can generate a new object instance, causing the interaction prior to drift away from the original object.

ROI contamination
In cluttered scenes, broad object attention can contaminate the DINO feature region and corrupt the final selection.
BibTeX
Citation
@inproceedings{zhang2026probing,
title={Probing and Bridging Geometry-Interaction Cues for Affordance Reasoning in Vision Foundation Models},
author={Zhang, Qing and Li, Xuesong and Zhang, Jing},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2526--2536},
year={2026}
}